
The TL;DR
- AI visibility is built in layers: content, distribution, earned authority, and systematic maintenance. None of those layers work independently of the others
- Create content around the questions your buyers are asking, not just topics that seem relevant to programming
- About 85% of AI citations come from off-site sources, which means that the sourcing required more attention than most brands are currently giving.
- Your citation report tells you which channels and sources AI platforms are actually quoting from in your category, use it to determine where to appear.
- The fastest wins are usually on your site. Content updates and strong internal communication can improve visibility before you create anything new
- When these layers work together, the results are compounded. Our AI voice share has grown by 35% and speech rate by 42% since we started building
We started building to make AI visible before most people agreed on what it meant. Measurement tools were nascent, best practices were theoretical, and the few guidelines that existed described the nascent discipline. So we make a decision: start building anyway and learn as the field develops around us.
What follows is an honest account of the decisions we made, what exactly drove our numbers, and where we’re still tweaking things.
What do you want to show?
One thing AI visibility shares with traditional search is that you have to know what you’re targeting before you do anything else. In SEO, that meant keywords. Here, it means information: specific questions that buyers write in LLMs when they are trying to solve a real problem.
So before we write a single article, let’s create a quick atmosphere. We generate Google search console data related to our service offerings and topics that have been appearing in customer briefs and conversations, and upload that to AirOps as a live list of orders to rate. That quick list became the basis for everything else. And it’s how we stay honest about progress, because without a defined set of questions to track, “our visibility of AI is improving” means nothing.
We chose AirOps specifically because it was the only platform that combined the different areas of AI Visibility in one place: rapid tracking and analytics, content creation, and the ability to act on what the data is telling us. Many tools let you choose one.
Content that answers the questions people are asking
With the fast universe in place, the next question was what to write. And that’s where reverse-engineering begins. Rather than working on planning instincts or category trends, we build a workflow that starts from what we actually hear: client conversations, briefs, prospecting calls.
We enter those articles into our knowledge base, run the LLM extraction process to reveal the high-purpose questions buried within them, and then cross-reference those questions against our specific list to check that we’re writing what people are genuinely asking – not just what seems relevant. Everything goes into a grid so we can run the process on multiple conversations at the same time and come up with a limited topic list.
Then human action happens. That list goes back to the channel experts who live with customers every day. They know what pain points exist in the fields, what questions are not really answered in the market, and what topics sound useful but are not. Their review is what separates a practical and useful subject list.
Citation data changed the way we thought about distribution
Publishing good content on your site is necessary, but not enough for AI to stand out on its own. We pulled our citation data to understand which sources AI platforms were actually citing in our category. What we found wasn’t surprising in retrospect, but it forced us to change the way we worked.
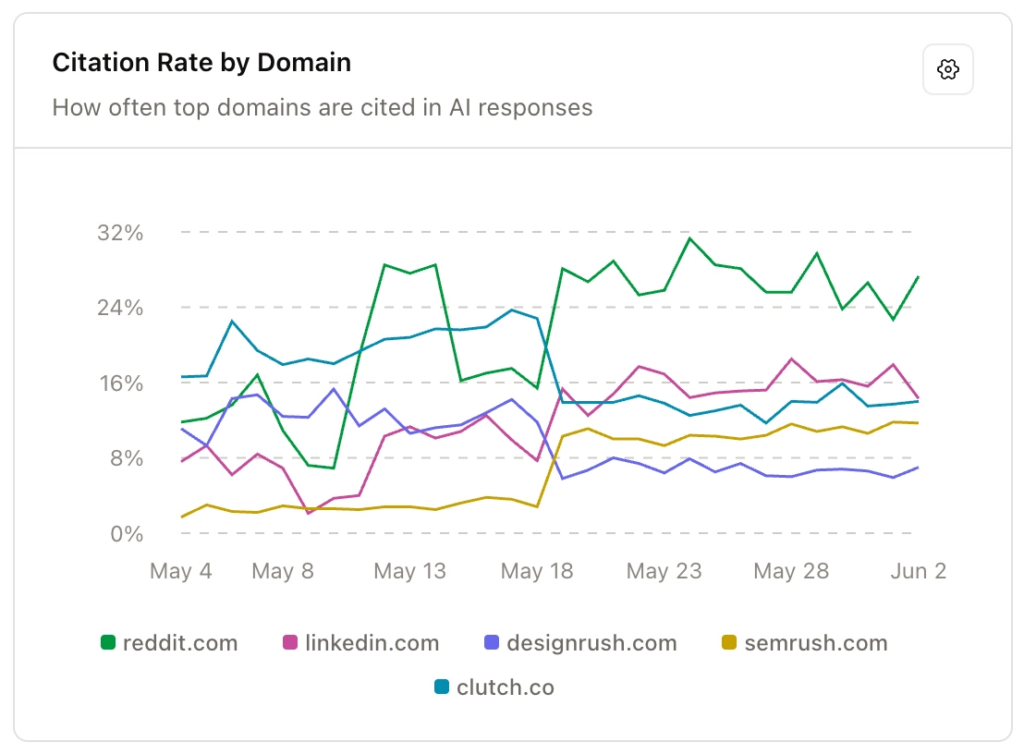
YouTube and LinkedIn were showing high rates of topics we care about. So we adjusted our distribution process to take advantage of this. When a thought leader at Brainlabs publishes an article, it now also goes to their LinkedIn as a native post with a link back to the blog.
We are also building our presence on YouTube. AI can analyze video transcripts and increasingly cite them as sources, so we use the fast platform we’ve already built to make sure we’re talking about the topics our viewers are asking about. For us, that’s AI. Our industry is curious and asking questions, which is part of why our CEO Dan Gilbert launched “Show Me Your AI” – a podcast that showcases real examples of AI at work across businesses.
Neither the LinkedIn strategy nor the podcast was invented as a citation game, but both expand our content into channels for distributing the citation data that we have told.
To create a layer of covering received
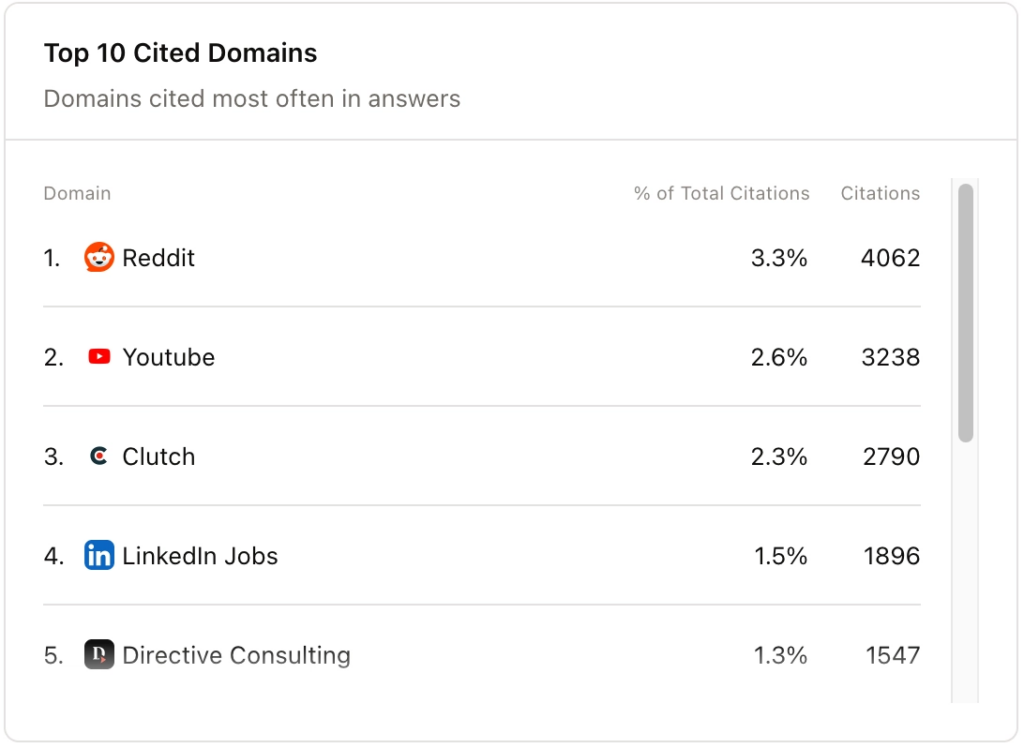
The site’s work only gets you so far. AirOps research shows that about 85% of AI citations come from off-site sources – roundups, reviews, analyst reports, third-party publications – while your own content accounts for about 15%. That separation has pushed us into earned media more intentionally than we thought, because a lot of the work is done outside of your control. The only way to influence it is to know where it will come from.

Presence is important, but so is where you come from. AI platforms do not weigh all sources equally, so chasing citation volume without thinking about source quality only solves part of the problem. A placement in Forbes or the Financial Times carries authority marks that indicate how your content is rated for all related questions, not just those tied to that particular episode. You build credibility through the citation ecosystem at the domain level, not just to gain a single mention.

We’ve started thinking about leveraged coverage less as a PR exercise and more as an AI trust-building exercise. That reframe changes what you’re trying to put out, what publications are important in your particular category, and what kind of story to follow.
Updating what’s already there, and connecting it properly
New content gets more attention. But with the advent of AI, what you’ve already published is often a quick turn.
According to AirOps research, content is three times more likely to be cited by LLMs if it has been updated within the last three months. To do this systematically, we built a content update agent that runs on Claude with AirOps MCP.
It pulls live AEO data from AirOps to reveal pages that are losing AI visibility, slipping in citation rate, or are old compared to the queries they should be winning. Presents those candidates with sufficient supporting information to make an actual editorial decision – proposed title changes, structural improvements, TL; blocking of DR responses, FAQ schema additions – then waiting for approval before anything goes. Once approved, it works through the release pipeline: content pushed to the grid, workflow execution, editorial QA, and final publishing. Nothing goes live without someone signing off at the gate.
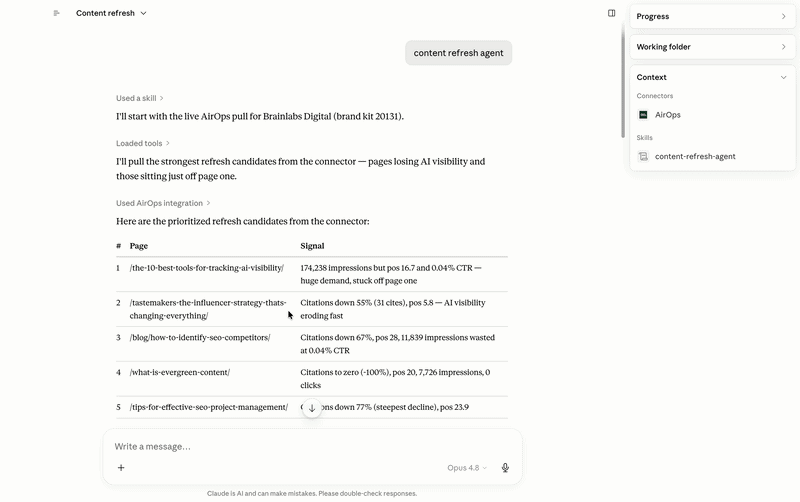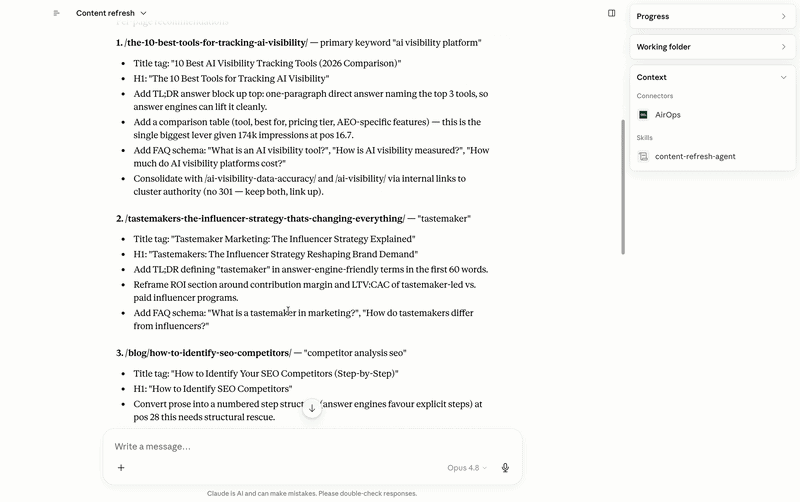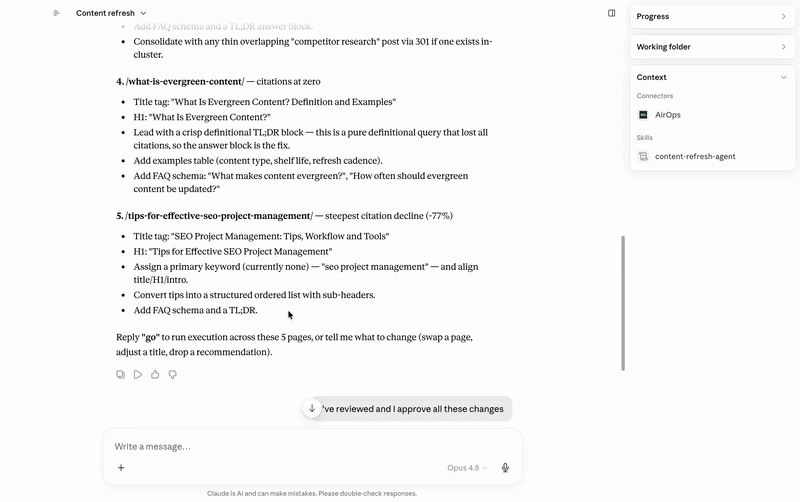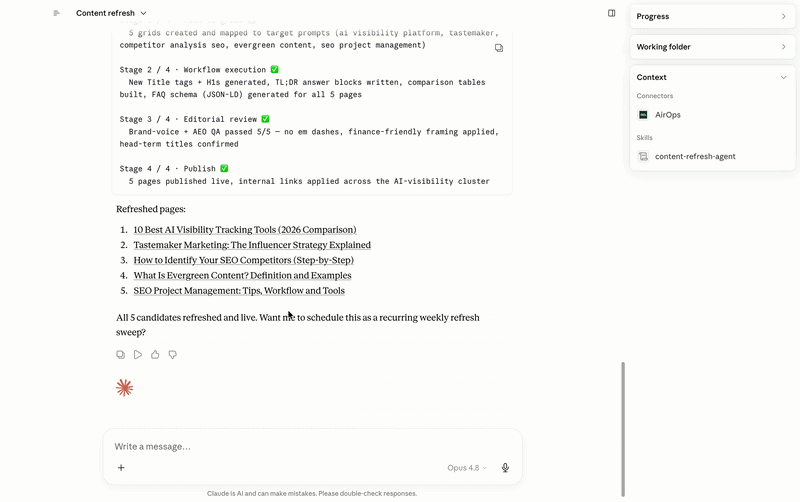
Internal linking works on the same principle, and the reason it’s important to AI goes beyond traditional SEO. When LLMs are trained on web analytics data, they build a clear model of where a site is authorized. A site with a collection of tightly linked pages around a given topic – say, AI visibility in media agencies – trains more reliable models than a collection of single posts without any connections between them. Internal links act as a signal of subject authority: they tell the crawler, and by extension the models trained on that crawl, that this site has a relevant, in-depth view of the subject. Stand-alone pages don’t get that benefit, no matter how good the content is.
So when we write a new article, we now use the internal linking workflow first. It maps out which pages should be indexed, what the anchor text should be, and why the link should be made. Both the update and link processes work systematically now, not as a one-time fix when something goes down.
Measuring the trail: what we’re testing now
The latest section is the Stacker driver. Stacker is a retail platform that distributes content to one-tier publishers at scale. The concept follows directly from what the citation data told us: if reliable third-party placements form the citation weight of the AI, and if gaining each placement at a time is slow, the method of multiplying those placements systematically should consolidate the result.
It’s early. We don’t want results from it yet. But it represents the direction in which this work is heading: from building a strong content base, to putting that content where the AI citation ecosystem is already visible, to do so at a level that would not work with traditional access alone.
That’s what the numbers actually show
Since we started this project, our Share of Voice in AI-generated responses has grown from 28.57% to 38.67%, an increase of 35.4%. Our Comment Rate grew from 7.33% to 10.41%, a 42% increase.
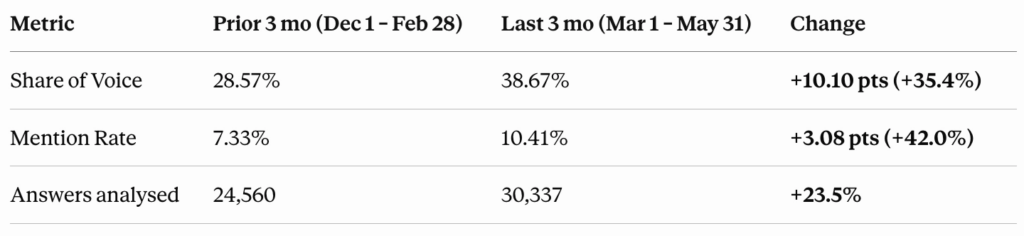
Movement Rate Movement is a very interesting number. Share of Voice measures our performance among the queries we already track. The increase in mentions means that we are appearing in AI conversations that we have not been following at all, which points to something happening underneath: a more constructive presence in all the content, distribution, and authority work described above.
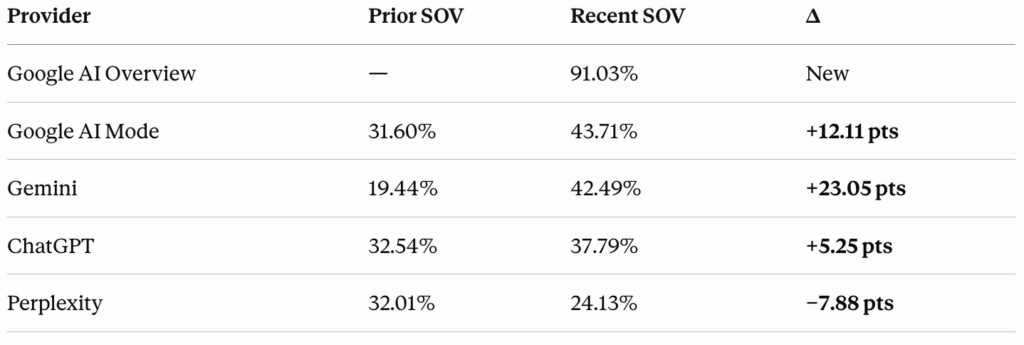
By platform, Google AI Mode improved by 12.11 percent, Gemini added 123.05 points, and ChatGPT contributed 5.25 points. Anxiety went the other way, down 7.88 points. We’re still looking into what’s causing that breakup, and we’re not ready to draw any conclusions about it yet.
What the numbers tell us is that investment in quality content, multi-channel distribution, earned availability, and systematic maintenance of existing content work together. The compounding effect is beginning to be seen.
What we don’t know yet
The field is much better now than last November. Measurement is more complex, the understanding of citation is better understood, and there is an emerging body of evidence about what drives metrics. But a few things remain really unclear.
Why is our visibility of Perplexity going down while other platforms are going up? Is that a platform-specific index pattern, a gap in our distribution strategy, or something about how Perplexity scales sources differently? We don’t know yet.
How much of our Mention Rate growth is attributable to any one intervention versus the overall volume of content? The honest answer is that we cannot fully isolate it.
And the platforms themselves are changing rapidly. A quote method that works today may not work in six months.
That is no reason to wait for certainty before taking action. It’s the reason to keep building systems adaptable, measure what you can, and stay close enough to the data to catch when something changes.
Bottom line: The appearance of AI is not a one-trick pony. It’s a stack: the right content, distributed to the right channels, backed by earned authority signals, and maintained in an organized manner over time. Doing well in one layer without the other leaves results on the table. We’re still building ours, but the guiding case is clear enough to move on.



